Introduction to Surveying and Discussion of Errors
Surveying is the science of determining the earth's dimensions and surface form by measuring
distances, directions, and elevations. It also covers staking out lines/grades for construction and the
computation of areas, volumes, and related quantities for preparing maps and diagrams.
Why it matters: surveys guide construction of buildings, roads, dams, and other structures by fixing positions and
elevations needed during layout and construction.
As-Built Surveys → Document the final positions and dimensions of features after construction.
Quick Reference
Plane vs. Geodetic: use plane for small sites — subdivisions, site grading, short roads.
Use geodetic for regional control networks, long routes, and high-accuracy mapping.
Measurements, Accuracy & Precision
Measurement is central to surveying, but no measurement is exact; the true value is never fully known.
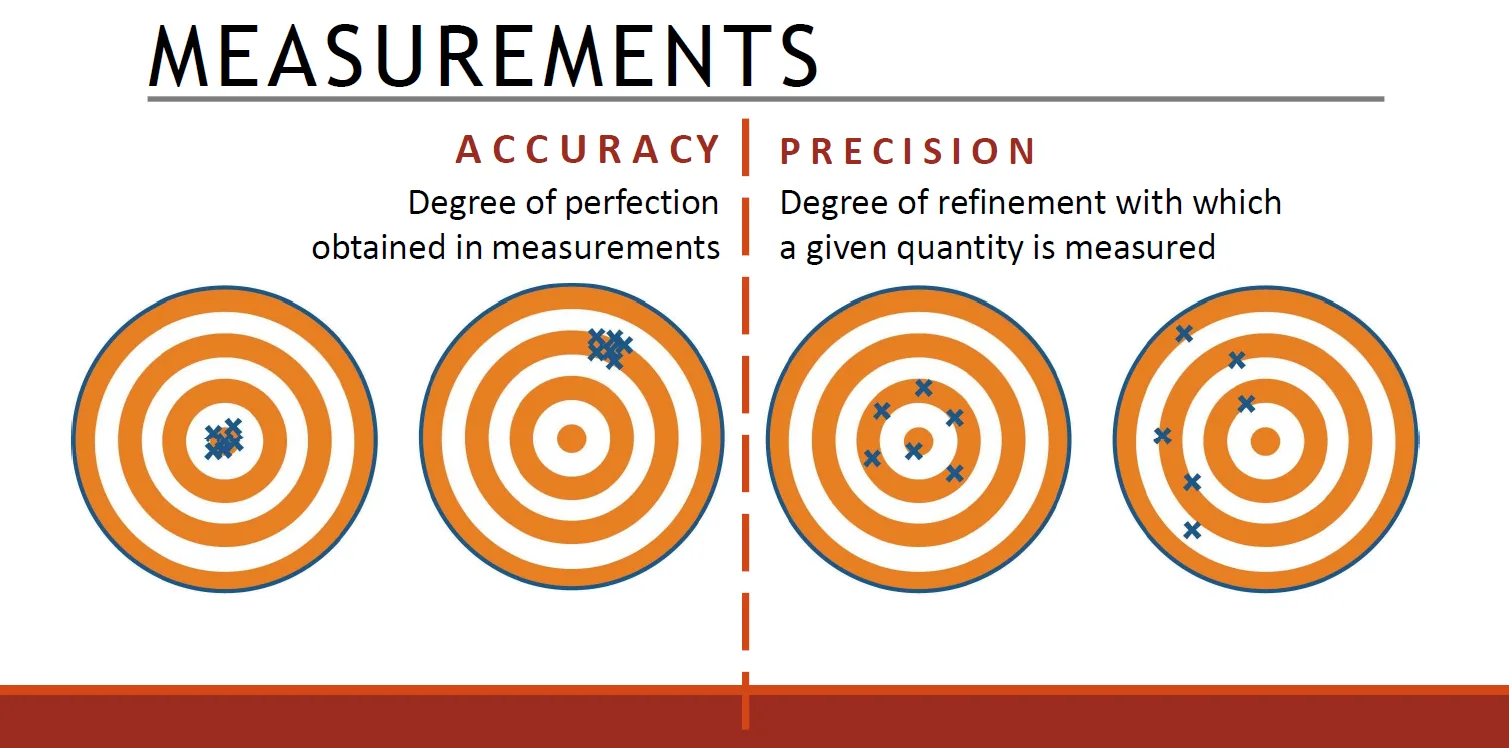
Accuracy = closeness to the true value (degree of perfection), while
Precision = repeatability or refinement of readings.
Aim: Use skill, judgment, and proper methods to make measurements as accurate and precise as practical.
Mistakes vs. Errors
Mistake (Blunder): due to inattention or misunderstanding; eliminable by careful checking.
Error (Unavoidable): due to limits of senses, instrument imperfections, or environment; cannot be eliminated
but can be minimized.
Relative / Probable Error
835.82 ± 0.06
The quality of a measurement can be expressed by stating a relative error.
Maximum Probable Value: 835.88ft
Minimum Probable Value: 835.76ft
Most Probable Value: 835.82ft
Probable error statements:
50% error: “There is a 50% chance that the error is ±0.12 ft or less and a
50% chance that it contains a larger error”
90% error: “There is a 90% chance that the error is ±0.12 ft or less and a 10%
chance that it contains a larger error”
Treating a Set of Repeated Measurements
Arithmetic Mean (assumed best/most-probable value): $\,\mu=\dfrac{\sum x_i}{n}\,$
Residuals (deviations): $\,v_i=x_i-\mu\,$
Standard Deviation (sample): $\,\sigma=\sqrt{\dfrac{\sum v_i^{2}}{n-1}}$
Why $n-1$? Imagine you're measuring how much students deviate from the class average — but you don't know the true class average, so you use your group's average. Since your group average is “tuned” to your group's own values, your spread will look smaller. Dividing by $n-1$ counteracts that, making the estimate closer to the true population spread.
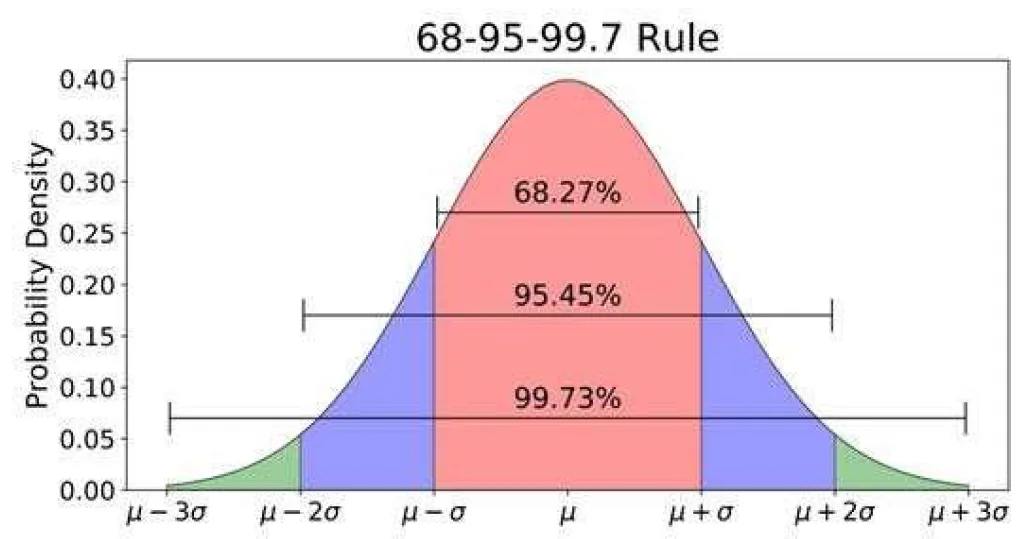
Probability (Normal) Curve insights:
There is 68.27% chance that the error is $\pm\sigma$ or less and 31.73% chance that the error is larger.
There is 95.45% chance that the error is $\pm2\sigma$ or less and 4.55% chance that the error is larger.
There is 99.73% chance that the error is $\pm3\sigma$ or less and 0.27% chance that the error is larger.
Tip: Compute $\mu$, tabulate $v_i$, then $\sum v_i^2$ to obtain $\sigma$ and make probability statements on your result.
Propagation of Accidental (Random) Errors
Series of Similar (Repeated) Measurements
Error of a Series of Similar Measurements When a series of quantities are measured, random errors tend to accumulate in proportion to the square root of the number of measurements. Error grows with the square root of the count:
$E_{\text{series}}=\pm E\sqrt{n}$, where $E$ is the error of each observation.
If a distance is measured a number of times with a probable random
error in each measurement, the probable error in the distance will
equal the total probable error in the number of observations divided by
the number of observations. Error of the mean (standard error): $E_{\bar{x}}=\dfrac{E_{\text{series}}}{n}=\pm\dfrac{E\sqrt{n}}{{n}}$
Series of Unrepeated Measurements
Combine independent probable errors in quadrature:
$E_{\text{total}}=\pm\sqrt{E_1^2+E_2^2+\cdots+E_n^2}$
Example themes from the PDF: combining errors for a tract's sides; angle series with a per-angle error to get a total
series error.
Measurements of a Single Quantity
$$E_p = C_p \sqrt{\dfrac{\sum v^2}{\,n-1\,}}$$
where $E_p$ = error for probability $p$;
$C_p$ = constant for probability $p$;
$v$ = residuals $\,\big(v_i = x_i-\bar{x}\big)$;
$n$ = number of observations.
To compute: find $\bar{x}$, list $v_i$, compute $\sum v_i^2$, then pick $C_p$ for your desired confidence (e.g., 90%) and evaluate $E_p$.
Probabilities for Certain Error Range (Normal Distribution)
Error (=)
Probability (%)
Probability that error is larger than value
$0.50\sigma$
38.3
$\approx$ 2 in 3
$0.6745\sigma$
50.0
1 in 2
$1.00\sigma$
68.3
1 in 3
$1.6449\sigma$
90.0
1 in 10
$1.9599\sigma$
95.0
1 in 20
$2.00\sigma$
95.4
1 in 23
$3.00\sigma$
99.7
1 in 333
$3.29\sigma$
99.9
1 in 1000
Reminder: use the sample SD with $n-1$ when the true mean is unknown. Intuition: if you estimate the mean from the same data, the spread looks smaller; dividing by $n-1$ counteracts that bias.
Interpretation: The most probable value is $152.91 \pm 0.136\ \text{ft}$ at 90% confidence, meaning the true value is likely between $152.774\ \text{ft}$ and $153.046\ \text{ft}$.
Problem 3:
A series of 12 angles was measured, each
angles with an
estimated error of ±20 seconds of arc. What is the total estimated error in the 12 angles?
Given:
Number of measurements: $n = 12$
Error in each measurement: $E = \pm 20''$
Interpretation: The total estimated error for the 12 angles is $\pm 69.28''$ (about $\pm 1'$ 9.28"), meaning that the accumulated random error across all measurements is larger than the error in a single measurement due to the square root accumulation rule.
Problem 4:
The four approximately equal sides of a tract of land were measured.
These measurements included the following probable errors: ±0.09 ft,
±0.013 ft, ±0.18 ft, and ±0.40 ft, respectively. Determine the probable
error for the total length or perimeter of the tract.
Interpretation: The probable error for the total length (perimeter) of the tract is approximately $\pm 0.45\ \text{ft}$.
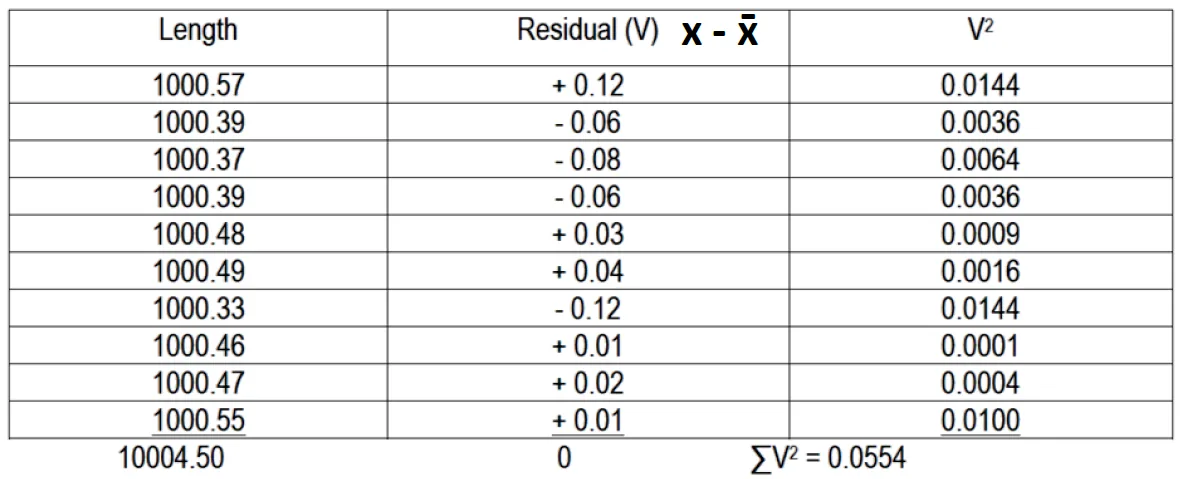
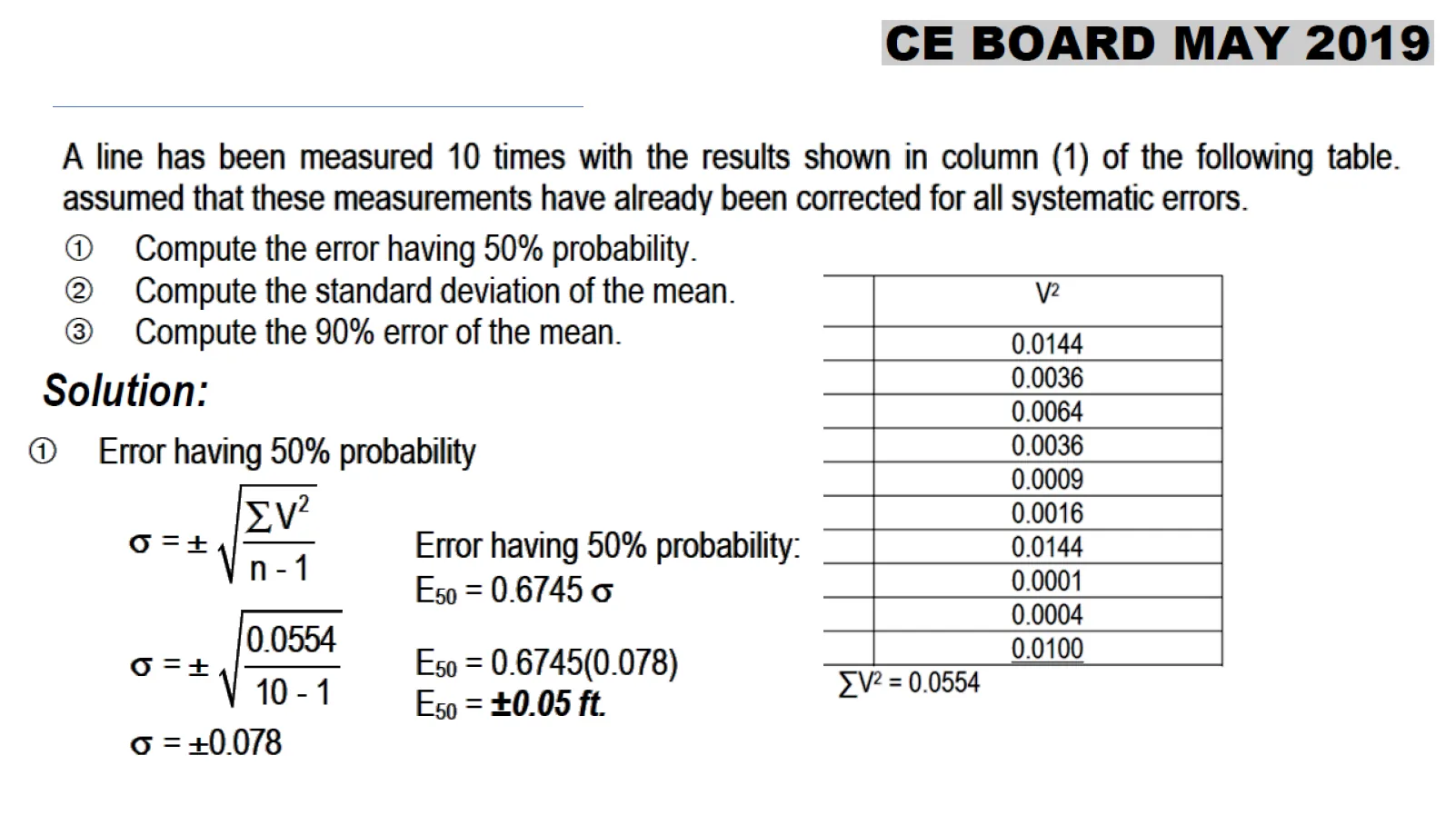
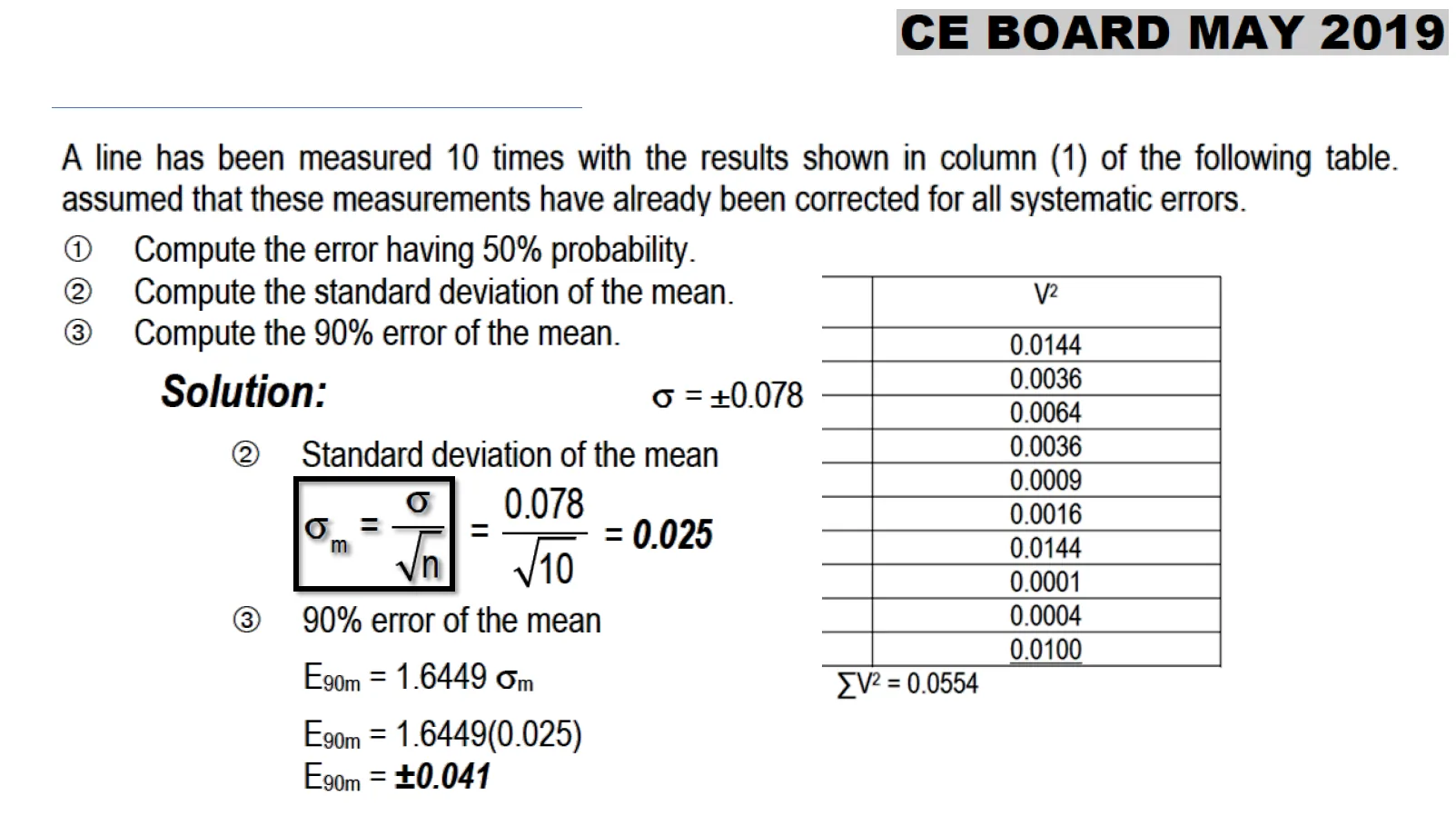
Problem 5:
CE Board Exam May 2019 A line has been measured 10 times with the results shown in column 1, assuming that the measurements have already been corrected for all systematic errors. 1. Compute the error having 50% probability 2. Compute the standard deviation of the mean. 3. Compute the 90% error of the mean.